K8s ConfigMap & Secret, Persistent Volume & Persistent Volume Claim

📍Introduction
🎇Welcome to my Kubernetes blog series, where I share my Kubernetes learnings and try to deep dive into topics. In this blog, we will explore the K8's intermediate concepts in detail and understand them by doing hands-on MySQL database service deployment. Let's get started!🚀
📍Scenario
Let's understand K8s ConfigMap, Secret, Ingress Controller, Persistent Volumes & Persistent Volume Claim by deploying MySQL database service in a Kubernetes Cluster and how we can use the above K8s services for it.
I am doing this on Minikube in an AWS instance. To install Minikube visit this URL. You can use K8s Playground in Killercoda i.e. a free resource to practice Kubernetes.
Let's deploy a MySQL database service on a Kubernetes cluster:
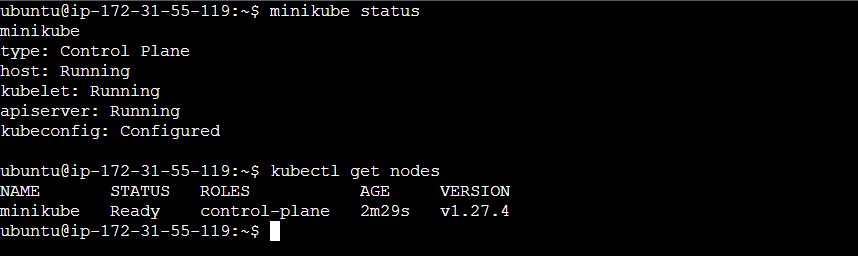
Step 1: Check Minikube status.
Step 2: Clone the below GitHub repository inside your home directory using the command git clone <URL>.
URL: https://github.com/Varunmargam/K8s_ConfigMap_Secret_PV_PVC.git

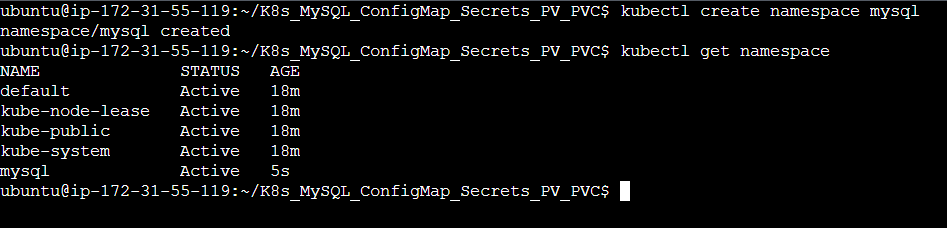
Step 3: Change the directory to K8s_ConfigMap_Secret_PV_PVC and create mysql namespace.

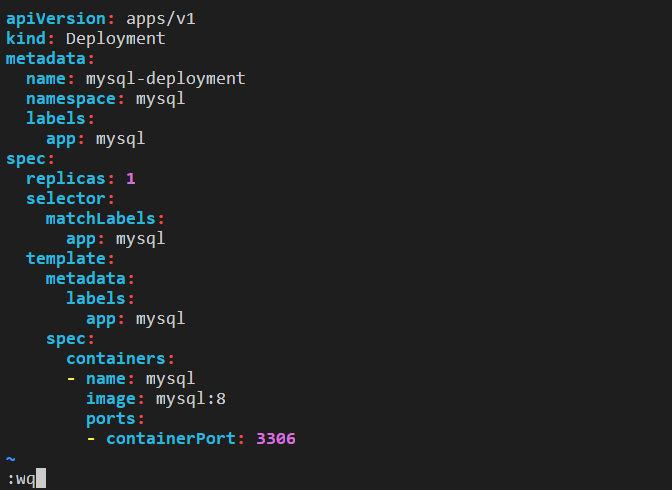
Step 4: Create a deployment file named deployment1.yml and copy the below content to deploy MySQL database service in the Minikube cluster.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
namespace: mysql
labels:
app: mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8
ports:
- containerPort: 3306

Step 5: Apply the deployment1.yml file using kubectl apply -f. Check the deployment and the pods in the cluster.
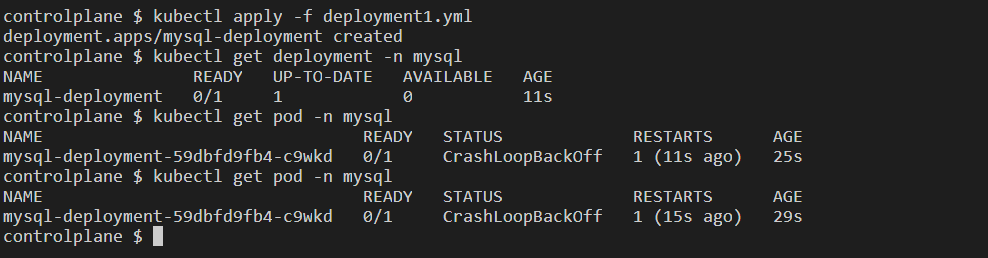
We can see that the pod running MySQL is in the CrashLoopBackOff state i.e. the container in the pod is crashing a restarting repeatedly. Because we have created a deployment file with replicas: 1 kubectl tries to maintain this state whenever the pod crashes. Since the container is repeatedly crashing kubectl creates a tight loop with increasing intervals to restart the container.
❓Why is the MySQL Container crashing❓
To run a MySQL service it needs some environment variables like Mysql_Database, Mysql_User, and Mysql_Root_Password. We need to give these environment variables to run the MySQL database service.
Step 6: Edit the deployment1.yml file using the Vim editor.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
namespace: mysql
labels:
app: mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8
ports:
- containerPort: 3306
env:
- name: MYSQL_DATABASE
value: "cooldb"
- name: MYSQL_ROOT_PASSWORD
value: root@123
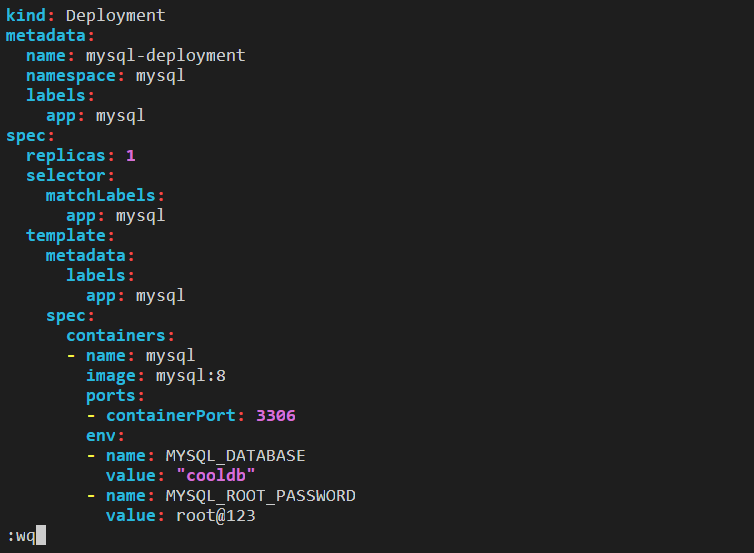
Step 7: Apply this edited deployment file and check the deployment and pod in mysql namespace.

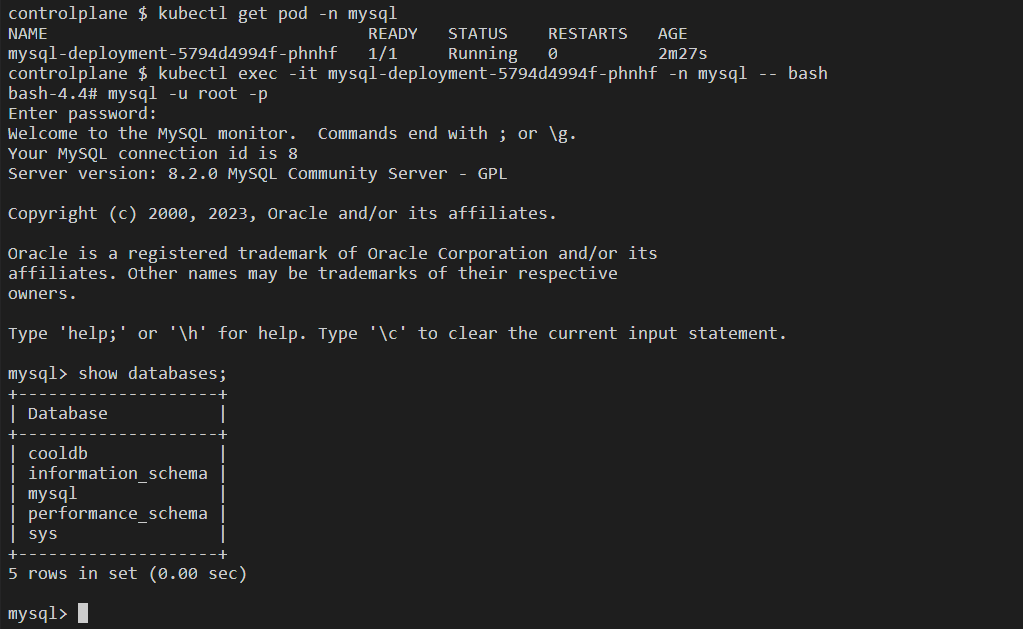
Step 8: Let's see if the database cooldb is created by the MySQL service.
kubectl get pod -n mysql
kubectl exec -it <pod_name> -n mysql -- bash
mysql -u root -p
Enter password: root@123
SQL query: show databases;
📍ConfigMaps & Secrets
Instead of giving the environment variables directly in the deployment file, we can create a separate manifest file called configmap where we can store configuration data and a secret manifest file where we can store sensitive data like passwords.
This helps us in easier management of configuration and sensitive data for the code like:
Separates configuration from the code which allows us to make changes in the configuration without modifying the application code.
For different environments like development, staging, and production configurations can be maintained separately.
It provides centralized management.
Configuration can be reused in multiple places, making deployment simpler and more efficient.
Updating configuration in one place allows for easy scaling across the application.
Ensures consistency in configuration settings across different application components.
Improves security by separating configuration data from application code and reducing exposure of sensitive information.
✔ConfigMap
Structure of ConfigMap Manifest file:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: my-namespace
annotations:
key1: value1
key2: value2
immutable: true
data:
key1: value1
key2: value2
...
apiVersion: This specifies the API version that the ConfigMap or Secret conforms to. For ConfigMaps and Secrets, it is typically "v1".
kind: This specifies the kind of resource. For ConfigMaps and Secrets, this is "ConfigMap" and "Secret" respectively.
metadata: This is a map that contains metadata about the resource.
namekey specifies the name of the resource.namespacekey specifies the namespace in which the resource resides.labelskey specifies labels that can be used to organize and select resources.annotationskey specifies arbitrary non-identifying metadata about resources. Eg: documentation, configuration, tool-specific settings, resource management (to control the behavior of the resource or the way it's treated by Kubernetes components or controllers), versioning, additional data, linking (related) resources, etc.immutable: This key is specific to the ConfigMap resource. When set to
true, it specifies that the ConfigMap should be immutable and cannot be modified after creation.data: This is a map where the keys and values represent the configuration data. In a ConfigMap, the values are strings. In a Secret, the values are base64-encoded strings.
✔Secret
Structure of Secret Manifest file:
apiVersion: v1
kind: Secret
metadata:
name: my-secret
namespace: my-namespace
type: Opaque
data:
key1: base64value1 # Value that is base64 encrypted for security reasons.
stringData:
key2: value2
...
📝Note: Note that if the same key is specified in both data and stringData, the value in stringData takes precedence. For example, if you have a key key3 in both data and stringData, the value in stringData will overwrite the value in data for key3.🖊
type: This key is specific to the Secret resource. It specifies the type of the secret. The most common type is "Opaque", which is used for arbitrary key-value pairs.
stringData: This key is specific to the Secret resource. It is similar to the
datafield, but the values are plain strings (not base64-encoded). ThestringDatafield allows you to specify non-base64 encoded data, and its values will be merged with thedatafield and encoded as base64.
The stringData field is used when you want to provide string data in a Secret resource without having to manually base64 encode it. It makes it easier to read, write, and update string data in a Secret.
📍Hands-on ( Continuing...)
Step 1: Check out the configmap.yml and secret.yml manifest files with the cat command.
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
namespace: mysql
labels:
app: mysql
data:
MYSQL_DATABASE: cooldb
apiVersion: v1
kind: Secret
metadata:
name: mysql-secret
namespace: mysql
labels:
app: mysql
type: Opaque
data:
MYSQL_PASSWORD: cm9vdEAxMjM= # I have encoded the password i.e. root@123 with base64 online editor.
📝Visit this online base64 encoder for encoding passwords: https://www.base64encode.org/
Step 2: Apply these Manifest files.


Step 3: Edit the deployment1.yml file with the following code.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
namespace: mysql
labels:
app: mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8
ports:
- containerPort: 3306
env:
- name: MYSQL_DATABASE # Key name of the environment variable
valueFrom:
configMapKeyRef: # Referencing ConfigMap Manifest
name: mysql-config # Providing config manifest name
key: MYSQL_DATABASE # Providing key name whose value should be taken
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: MYSQL_PASSWORD
Step 4: Apply the deployment1.yml file using the command kubectl apply -f deployment1.yml
Check the deployment and pod in the cluster:
kubectl get deployment -n mysql
kubectl get pod -n mysql
If you have followed everything correctly then the MySQL pod will be running successfully.
📍Persistent Volumes & Claims
In Kubernetes, applications can be broadly categorized into two types:
Stateless
Stateful
🎇Stateless Applications
These are applications that do not store any data or have any persistent state. This means that they don't care about what happened in the previous session and they don't need to store data across sessions or pod restarts.
Example:
This blogging website has articles, pictures, and videos. It doesn't remember anything about you or anyone else who visits the site. It doesn't need to store any special data for each visitor. Unless you create an account and add some content to your profile. Since this data does not store any special data for each visitor and just shows articles, pictures, and videos to everyone it is a stateless application.
🎇Stateful Applications
These are applications that store data and have a persistent state. This means that the data generated or modified by the application needs to be stored and retrieved across sessions, pod restarts, or even cluster failures.
Example:
Imagine an e-commerce website an online store where you can shop for products. It remembers who you are (user data), what products are available (product information), what's in your shopping cart (shopping cart details), and what you've bought in the past (order history) along with your account details. This website needs to remember this information even if it gets shut down and restarted, or even if it moves from one computer to another inside its hosting environment. This data which is being persisted (stored) makes it a stateful application.
To create such Stateful Applications like the E-commerce website we saw in the above example we use tools like PV (Persistent Volume) and PVC (Persistent Volume Claim) in Kubernetes to persist the data. It is similar to volumes in Docker. Since everything in Kubernetes is a Manifest file we have to create a Manifest file for both PV and PVC.
✔Persistent Volume
A Persistent Volume (PV) is a representation of a physical storage resource in a Kubernetes cluster. It's like a big storage box that has been created and made available for use by an administrator or dynamically using storage classes. It provides a place where data can be stored persistently, like a storage box where you can store your files and data.
For example, in a MySQL database scenario, a PV can be used to allocate a specific amount of storage space for the MySQL database files, ensuring that the data is stored safely and is available even if the database restarts or moves within the cluster.
General Structure of PV Manifest file:
apiVersion: v1
kind: PersistentVolume
metadata:
name: <PV_NAME>
spec:
capacity:
storage: <STORAGE_AMOUNT>
accessModes:
- <ACCESS_MODE>
storageClassName: <STORAGE_CLASS_NAME>
persistentVolumeReclaimPolicy: <RECLAIM_POLICY>
<STORAGE_TYPE_SPECIFIC_PARAMS>
metadata.name: The name of the PV.capacity.storage: The amount of storage allocated to the PV.accessModes: The access modes that determine how the PV can be accessed.storageClassName: The storage class name used for the PV.In terms of options, there can be as many StorageClasses defined in your Kubernetes cluster as needed, each with its name. The names of the available StorageClasses can be retrieved by running
kubectl get storageclasses.persistentVolumeReclaimPolicy: The policy that determines what happens to the data when the PV is released. There are 3 options mainly 2 available for the Persistent Volume Reclaim Policy:Retain: Data is kept when the PVC is deleted, but the PV must be manually reclaimed by an admin.
Delete: Both the PV and its data are deleted when the PVC is removed. This is used with dynamically provisioned storage.
Recycle (deprecated): This policy is no longer recommended and has been replaced by dynamic provisioning.
<STORAGE_TYPE_SPECIFIC_PARAMS>: Parameters specific to the storage type being used (e.g.,hostPath,nfs,awsElasticBlockStore, etc.).
✔Persistent Volume Claim
A Persistent Volume Claim (PVC) is a request for storage resources by a user or an application in a Kubernetes cluster. It's like asking for a portion of the storage box to use for your stuff. It's used to claim a specific amount of storage space from a Persistent Volume (PV).
For example, in a MySQL database scenario, a PVC can be used to request the specific amount of storage space needed for the MySQL database files. The PVC then allows the MySQL database to use that space to store its files and data, ensuring that the data is stored persistently and is available across sessions and restarts.
General Structure of PVC Manifest file:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: <PVC_NAME>
spec:
accessModes:
- <ACCESS_MODE>
storageClassName: <STORAGE_CLASS_NAME>
resources:
requests:
storage: <STORAGE_AMOUNT>
name: The name of the PVC.accessModes: The access modes that determine how the PVC can access the PV. There are 3 main options:ReadWriteOnce (RWO): This means that one node can use the storage to both read and write data, but no other node can use it at the same time.
ReadOnlyMany (ROX): This means that many nodes can use the storage to read data, but they can't change (write) the data.
ReadWriteMany (RWX): This means that many nodes can use the storage to both read and write data at the same time.
Here, a "node" refers to a physical or virtual machine (computer) that is part of the Kubernetes cluster. Each node runs one or more "pods," and each pod can contain one or more "containers" which run the applications (apps).
storageClassName: The storage class name used for the PVC. Similar to the PV.The
storageClassNamefield in a PV is used to specify the StorageClass that should be used when provisioning the PV. This field tells Kubernetes which StorageClass the PV belongs to, and it is used to match the PV with PVCs that have the samestorageClassName.The
storageClassNamefield in a PVC is used to specify the StorageClass that should be used to provision a new PV for the PVC. When a PVC is created, it will be bound to an available PV with the samestorageClassName. If no PV with the matching StorageClass is available, a new PV will be dynamically provisioned using the specified StorageClass, if it supports dynamic provisioning.spec.resources.requests.storage: The amount of storage requested by the PVC.
A Persistent Volume Claim (PVC) in Kubernetes serves several key purposes:
Request and Bind Storage: A PVC allows a user or application to request and reserve a specific amount of storage from a PV.
Mount Storage to Pods: PVCs enable the mounting of storage provided by a PV into a pod, allowing applications to read and write data.
Dynamic Provisioning: PVCs support dynamic provisioning, enabling on-demand creation of PVs based on storage requirements.
Access Control and Management: PVCs offer fine-grained access control and simplified management of storage resources.
📍Hands-on ( Continuing...)
Continuing our MySQL scenario we will be persisting the MySQL data directory. The data directory is where MySQL stores its database files, including table data, indexes, and log files. The location of the data directory can vary depending on the MySQL configuration and the operating system, but it is typically located in /var/lib/mysql by default.
Step 1: Create a directory named volume inside the Minikube at the worker node using the minikube ssh command and then exit the Minikube.
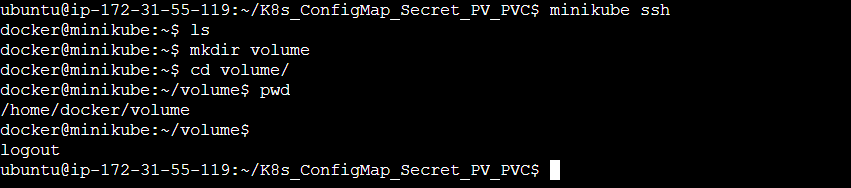
Step 2: Checkout the persistentVolume.yml and persistentVolumeClaim.yml manifest file.
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv
namespace: mysql
labels:
app: mysql
spec:
storageClassName: manual
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/home/ubuntu/volume" # Create a directory name volume and give that path of the directory
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
namespace: mysql
labels:
app: mysql
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi # I claimed 1 GB of storage form the available 2 GB storage
Step 3: Apply these Manifest files.


Step 4: Updating the deployment file for mounting this volume to our deployment i.e. our desired state. It is present in the deployment.yml file.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
namespace: mysql
labels:
app: mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8
ports:
- containerPort: 3306
env:
- name: MYSQL_DATABASE
valueFrom:
configMapKeyRef:
name: mysql-config
key: MYSQL_DATABASE
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: MYSQL_PASSWORD
# Mounting volume
volumeMounts: # inside the container
- name: mysql-persistent-storage # Here we specify the path of the data inside the container that we want to persist
mountPath: /var/lib/mysql # In our case we want to persist mysql data at this path.
volumes:
- name: mysql-persistent-storage # Here we specify the claim that we want to bind with the container data path.
persistentVolumeClaim:
claimName: mysql-pvc
mysql-persistent-storage is the name we have given to the folder from the path /var/lib/mysql inside the mysql container. mysql-pvc contains the disk path, therefore by doing this the container path and the disk path outside the container have been bound.
Step 5: Apply this modified deployment file i.e. deployment.yml file.


Now let's add some data inside the database and check if the data persist in our system at the given path.
Step 6: Enter the MySQL container using the kubectl exec -it <pod_name> -n <namespace> -- bash command and the following steps we did previously.
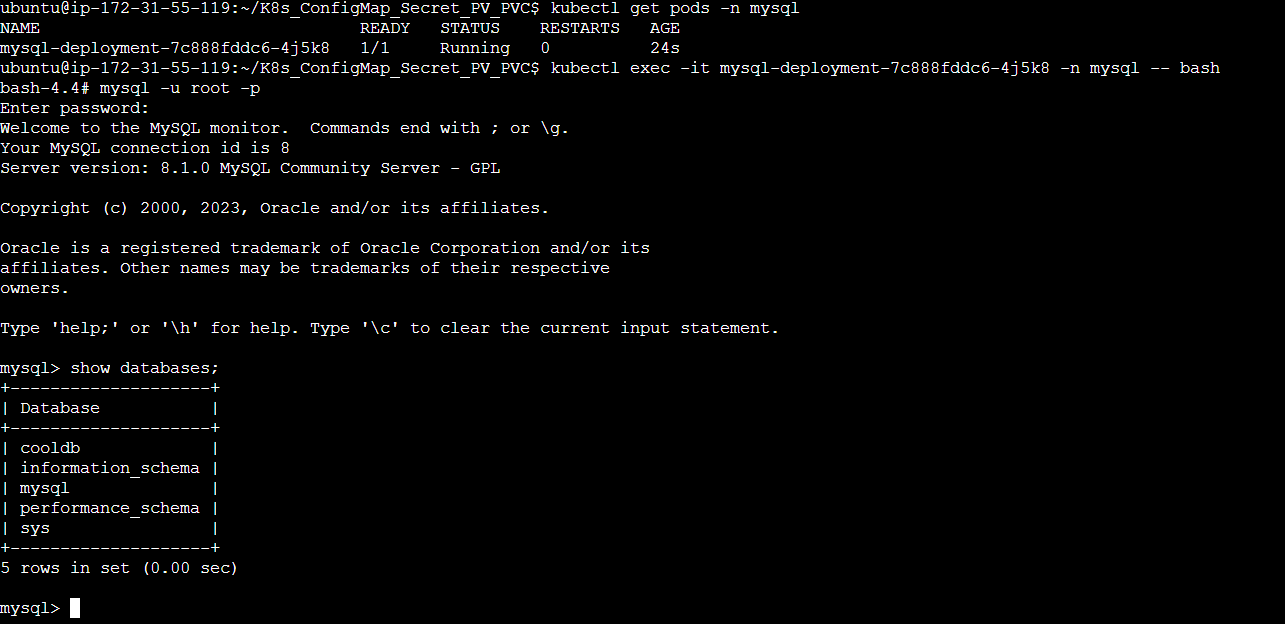
Step 7: Create a table example inside the cooldb database and enter some data inside the table.
SQL Query:
use cooldb;
CREATE TABLE example (id INT, data VARCHAR(100));
INSERT INTO example (id, data) VALUES (1, 'Hello World');
SHOW TABLES;
SELECT * FROM example;
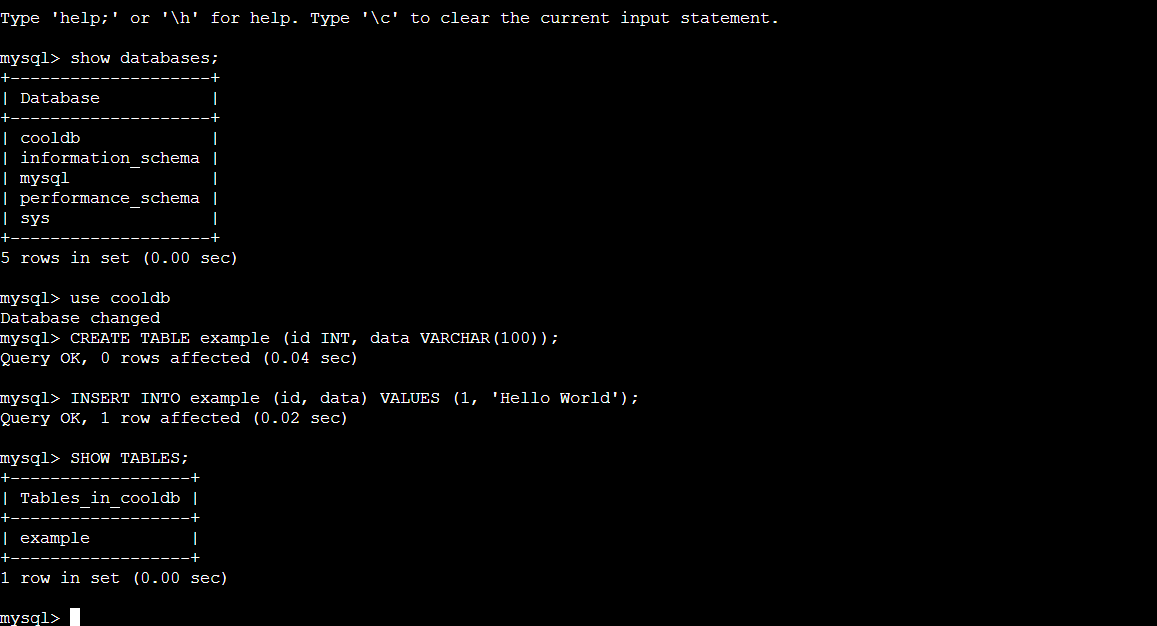
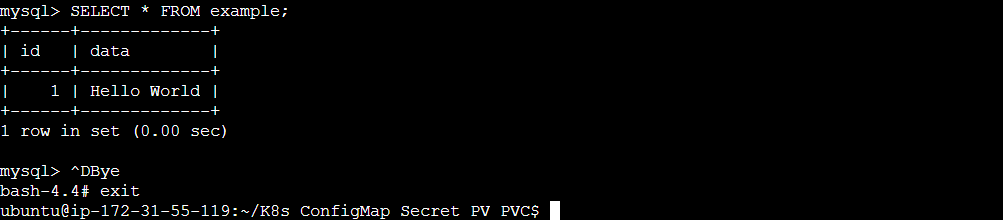
Exit the MySQL container and the pod with the command exit
Step 8: Delete the pod and kubectl will then create a new pod maintaining the desired state (Auto healing).

Step 9: Now let's exec into this new pod and see whether the data entered in the previous pod is present in this new pod.
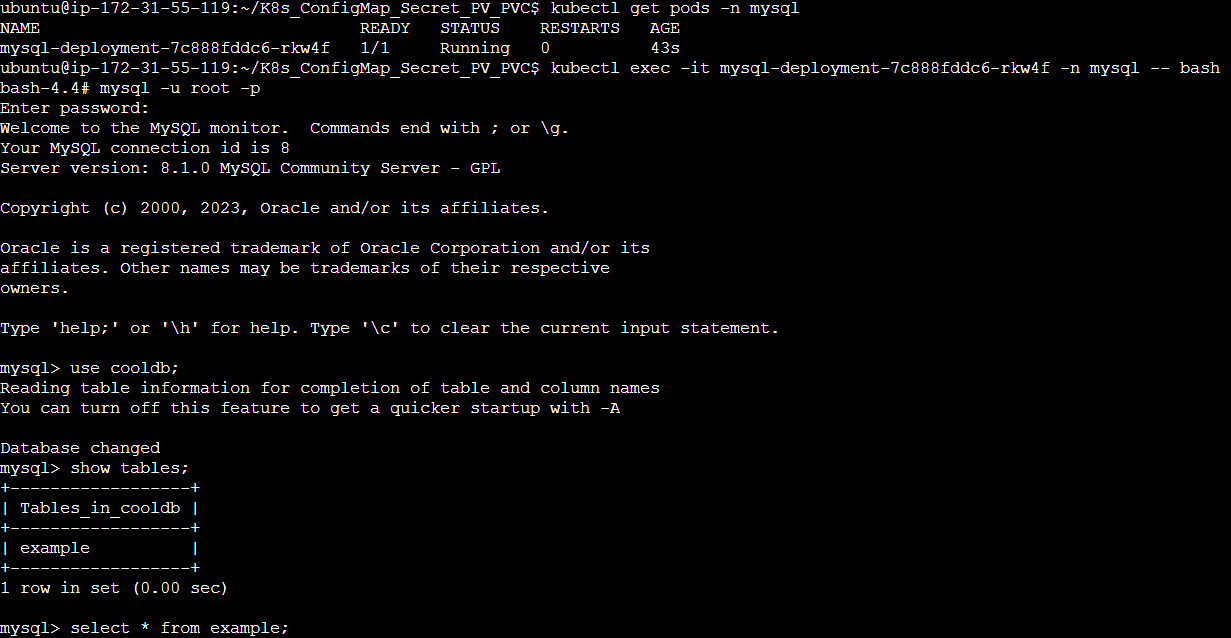
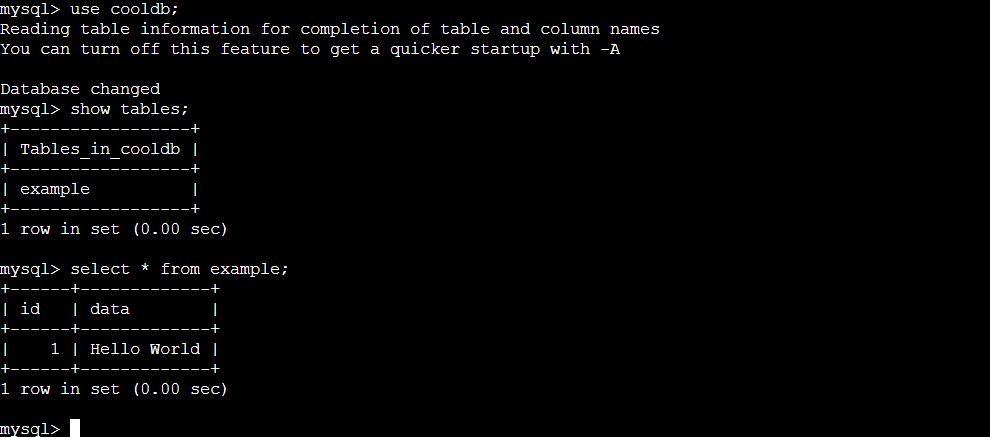
As you can see the data entered in the previous pod persists in this new pod. In this way, we can persist the data using PV and PVC and create stateful applications.
A question may arise...
❓Where is this data stored in the system❓
Ans - The data is stored at the specified path, /home/ubuntu/volume ( inside the home directory), in the worker node within the Kubernetes Cluster as defined in the Persistent Volume Manifest file. Let's see the persisted data at the specified path.
Step 10: SSH to Minikube and check the /home/ubuntu/volume path.
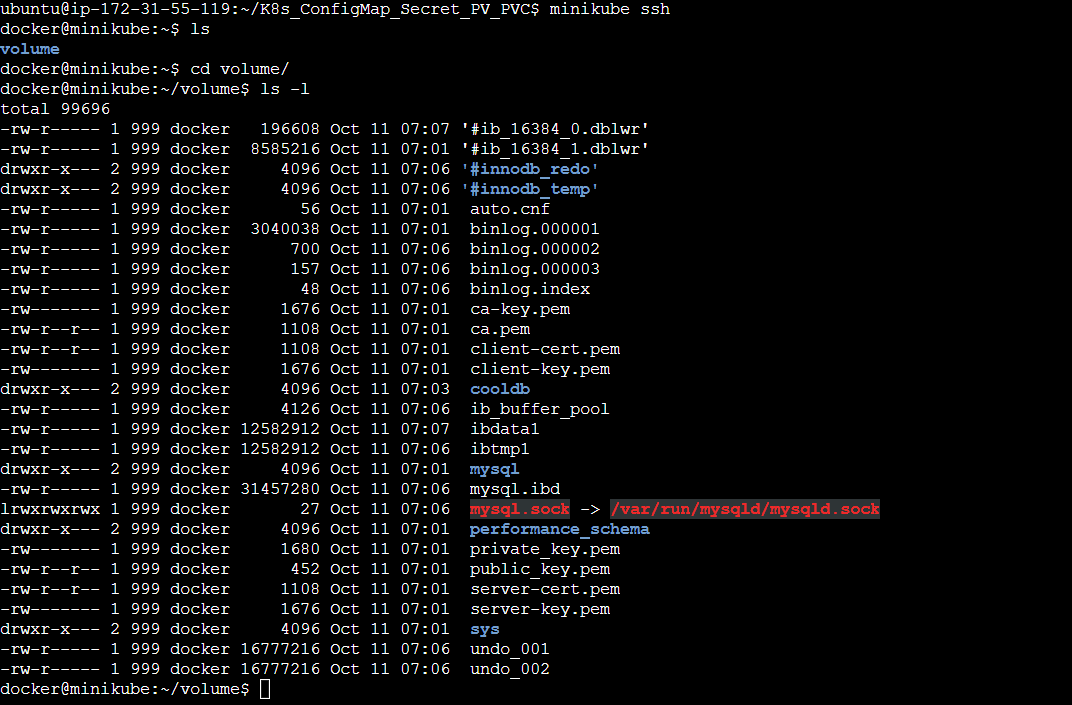
The data within the /var/lib/mysql directory has been successfully persisted in the worker node of the Kubernetes Cluster.
📍Conclusion
We have reached the end of the blog, where we explored concepts of Kubernetes ConfigMap, Secret, Persistent Volume, and Persistent Volume Claim. Thank you for reading this blog! 📖 Hope you have gained some value. If you want to practice Kubernetes make sure you do it on Minikube, Kubeadm or at killercoda.com where you get K8s playground for free.🚀
If you enjoyed this blog and found it helpful, please give it a like 👍, share it with your friends, share your thoughts, and give me some valuable feedback.😇 Don't forget to follow me for more such blogs! 🌟

